概述
背景
Stable Diffusion 最初是由德国慕尼黑大学的 CompVis 研究小组、纽约的 RunwayML 公司等组成的国际研究团队开发的,后来 Stability AI 参与其中并推动了其发展。
Stable Diffusion 的发展历程如下: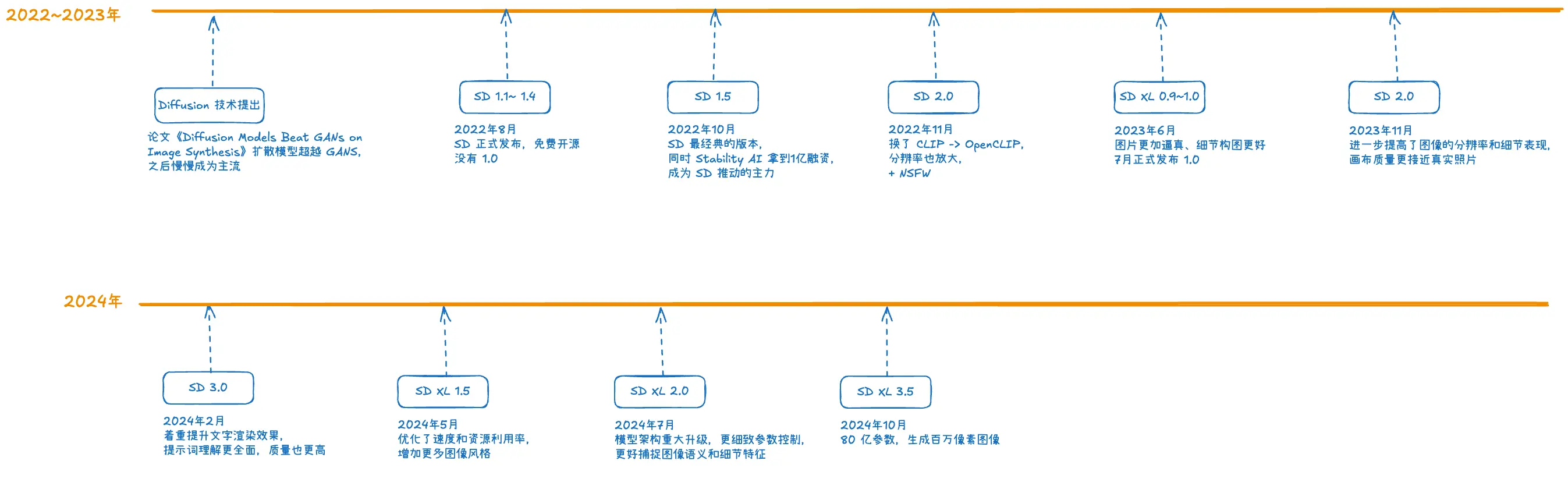
技术简介
Stable Diffusion 在模型架构中采用了 Transformer 架构的一些特性,基于扩散模型架构来生成图片。
它的原理用白话说,比较简单:加噪和去噪(专业术语叫前向扩散和反向扩散)。加噪后的图片主要用于训练或作为初始输入(latent),然后训练一个模型去实现某些图像生成目标(去噪过程)。
- 前向扩散:在前向阶段,通过向原始图像数据(如真实的照片或绘画)添加噪声,逐步将图像转换为纯噪声。这个过程是在多个时间步(time - steps)中完成的,每一步都按照一定的规则(通常是基于高斯分布)添加噪声,使得图像信息逐渐被噪声掩盖。例如,开始时图像可能还比较清晰,随着时间步的增加,图像越来越模糊,最终变成完全的噪声。
- 反向扩散:这是生成图像的关键阶段。从纯噪声开始,模型通过学习到的去噪过程,逐步恢复图像信息。模型会预测每个时间步中需要去除的噪声,经过多个时间步的迭代,最终生成一张类似于训练数据分布的图像。这个过程类似于从无序的噪声中逐渐 “雕刻” 出有意义的图像。
生图过程
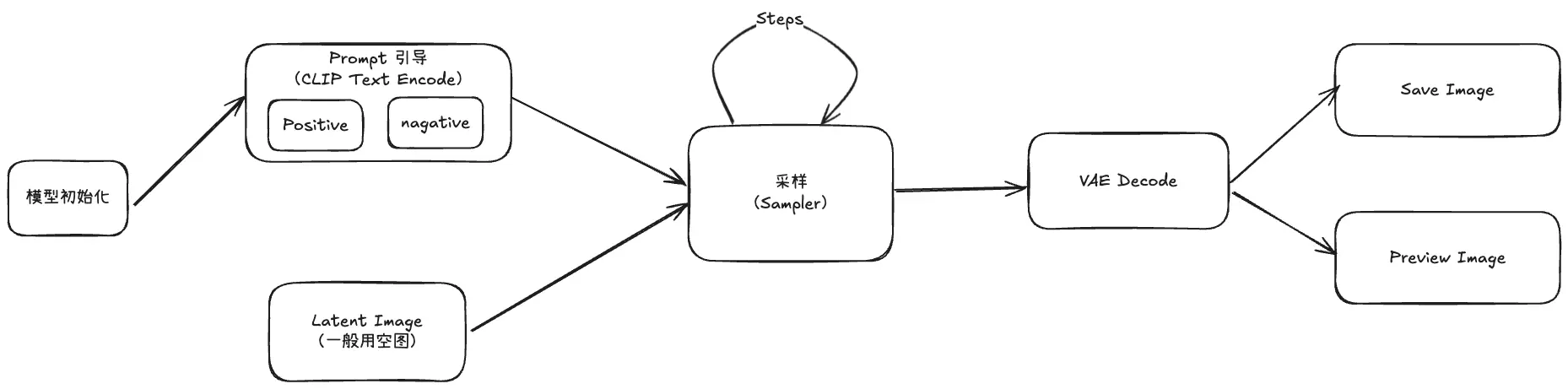
模型 (Checkpoint)跟采样的关系
Checkpoint 包含了模型在特定训练阶段的所有权重、偏置以及优化器的状态等信息,而采样模型的参数是由 Checkpoint 所确定的,采样模型使用该 Checkpoint 中存储的权重和其他参数进行计算。不同的 Checkpoint 会导致采样模型在生成图像时表现出不同的性能和风格。例如,某些 Checkpoint 可能侧重于生成高分辨率的图像,而另一些可能更擅长生成具有特定艺术风格的图像。这是因为在训练过程中,不同的 Checkpoint 所对应的训练数据和训练目标可能有所不同,从而影响了采样模型的行为。
CLIP Text Encode
属于 Condition 节点,它用 CLIP 模型对文本 Prompt 进行编码,对模型生成的结果进行方向上的引导,其实可能理解为文本模型中的 embedding。
采样
生图其实就是一个反向扩散的过程,从一个完全是噪声的图像开始,通过模型逐步去除噪声来生成图像。这个过程通过一个采样函数来实现,它基于模型预测的噪声来更新噪声图像。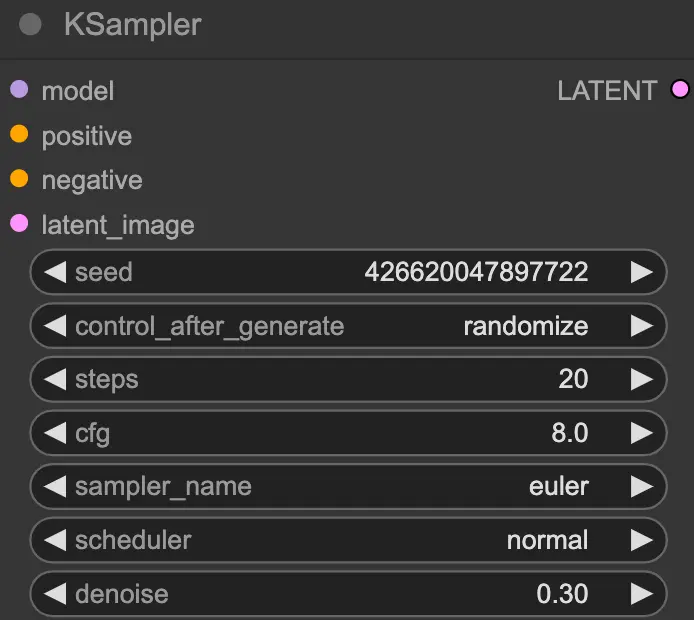
- Steps,迭代生图,每次更新噪声图像,需要经过多个 Step 的迭代。随着 Step 反复执行,图像中的噪声逐渐减少,最终生成一个近似原始图像分布的图像。不过生成的图像质量可能会受到多种因素的影响,如模型的性能、采样方法、时间步数等。在实际应用中,可能需要对生成的图像进行后处理(如调整颜色、对比度等)来提高图像质量。
- seed,种子值,用于初始化随机数生成器。相同的种子值在相同的模型和参数设置下会生成相同的图像,这有助于复现结果。
- control_after_generate:这个参数可能与生成后的控制操作有关,例如对生成的图像进行随机化处理
- steps:指生成过程中的迭代步数。步数越多,生成的图像通常会越精细,但也会增加计算时间。
- cfg(Classifier-Free Guidance):无分类器引导的强度,它是一种在生成式模型(如 Stable Diffusion)中用于引导图像生成方向的技术,决定了模型在生成图像时对正向提示(你希望在图像中出现的内容)的遵循程度。较高的 CFG 值会使生成的图像更紧密地遵循正向 Prompt,但也有可能导致图像过度拟合。
- 取值范围:
- CFG 的值通常在 1 到 20 之间,理论上可以取更高的值,但在实际应用中,过高的值往往会导致图像质量下降。
- 较低值(1 - 4):
- 当 CFG 值较低时,生成的图像会更具随机性和创造性。模型对正向提示的遵循程度较弱,因此可能会生成一些与提示不太相关但具有独特创意的图像。这种情况下,图像可能会包含一些意外的元素或风格。
- 中等值(4 - 10):
- 在这个范围内,是比较常用的取值。模型会在遵循正向提示和保持一定的创造性之间取得较好的平衡。能够生成与提示较为符合的图像,同时也不会显得过于刻板。
- 较高值(10 - 20):
- 当 CFG 值较高时,生成的图像会非常紧密地遵循正向提示。这可能会导致图像过于 “完美” 地符合提示,但也可能会出现一些问题,比如图像的细节可能会显得不自然,色彩可能会过于饱和,或者图像可能会失去一些自然的随机性和美感
- 取值范围:
- sampler_name:这是指采样器的名称。不同的采样器(如 Euler、Langevin 等)有不同的特性,会影响图像生成的速度和质量。
- scheduler:调度器,用于控制生成过程中的步长和其他参数。不同的调度器会影响生成的效率和结果。
- denoise:去噪参数控制生成过程中对噪声的去除程度。较低的去噪值会使生成的图像更具随机性,而较高的值会使图像更平滑和可预测。
VAE Decoder(变分自解码器)
图像数据往往是高维的,包含大量的像素信息,所以一般训练和计算时,往往要压缩到低维来处理,用更紧凑的方式表示图像的关键特征,就像文本模型中的 Embedding 处理,变成稠密的数据,在图像处理领域叫潜在空间(Latent Space)。而解码器则是将潜在空间中的表示再转换回图像数据空间,尽可能地重建原始图像。
生成新图的过程,由于潜在空间是连续的,稍微改变潜在空间中的向量值,就可以生成与原始图像在某些特征上有所变化的新图像。例如,在生成人脸图像的 VAE 模型中,在潜在空间中沿着某个方向移动向量可能会改变人脸的表情、发型或者年龄等特征。
Latent Image
一般在整个 ComfyUI 流程中,会插入一张空的(Empty) Lantent Image,它提供了一个初始的 “画布”,让模型在这个基础上进行生成或转换操作。
当然如果是对已有的图片进行调整、修复或优化,则可以把空的图换成一张现成的图片,这时就要把它加载并转换为合适的潜在表示形式后,可以作为生成过程的起点。在 ComfyUI 中,可能涉及到将图片通过适当的预处理步骤,如调整大小、归一化等操作后,然后将其编码为潜在空间中的表示,这样就可以基于已有的图像内容进行修改、风格转换或者其他生成操作。
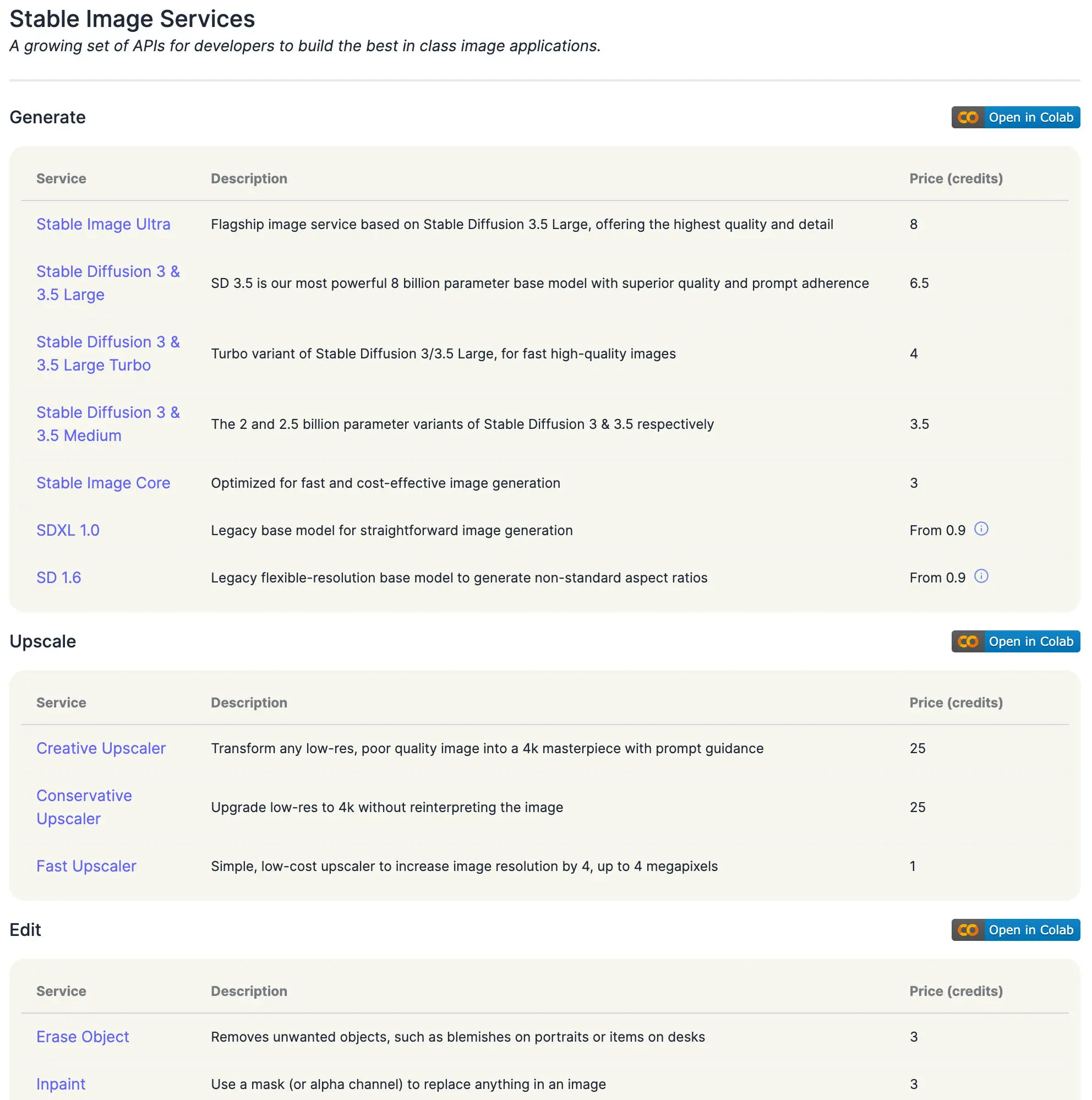
Stability AI 官方
Stable Diffusion 的官方可用的模型,可以从 API 文档中看到: Stability AI - Developer Platform。最新的是 SD 3.5(2024 年 11 月)。
- 1 credit = $0.01
- 这么算,生成一张 SD 3.5 的图片,medium 要 $0.035,差不多 0.25 元,4 张 1 块。
体验
Free AI Image Generator - Turn Text to Image Online | Stable Diffusion Online
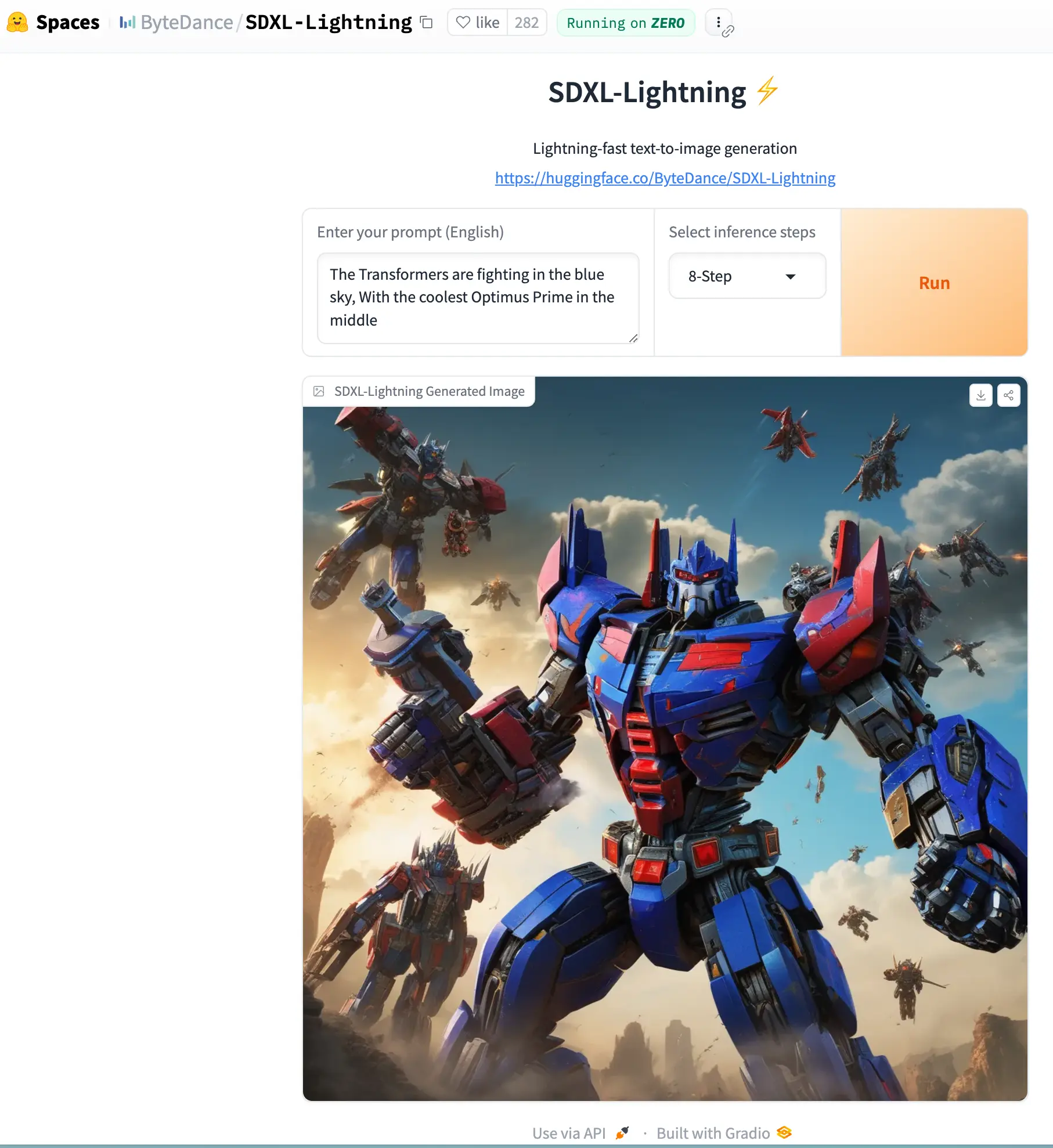
字节的 Lighting 模型
ByteDance/SDXL-Lightning at main 字节的这个模型生成效果相当不错。
它同时提供了 Full UNet 和 LoRA 版本,都是相对比较小的蒸馏模型(虽然 UNet 也有几个 G)。
We provide both full UNet and LoRA checkpoints. The full UNet models have the best quality while the LoRA models can be applied to other base models.
小科普(可跳过)
概念
- UNet 是卷积神经网络(CNN)的一种特殊架构,在生成对抗网络 (GANs) 和扩散模型中广泛使用。它是一种完整的网络架构,专门用于图像分割任务,从输入图像到输出分割结果,有自己独立的结构和训练流程。
- LoRA 不是一种独立的网络架构,而是一种模型微调策略,可以应用于各种现有的预训练模型(包括但不限于基于 UNet 架构的模型),用于在不大量修改原始模型结构的情况下进行任务适配。
从参数规模与训练成本来看
- UNet:在训练过程中,需要对整个网络的参数进行学习和更新,尤其是在处理高分辨率图像或复杂任务时,可能需要大量的训练数据和计算资源。
- LoRA:通过低秩分解减少了需要训练的参数数量,在对大型预训练模型进行微调时,训练成本显著降低,对数据量的要求也相对较少。
UNet 的模型一般都比较大: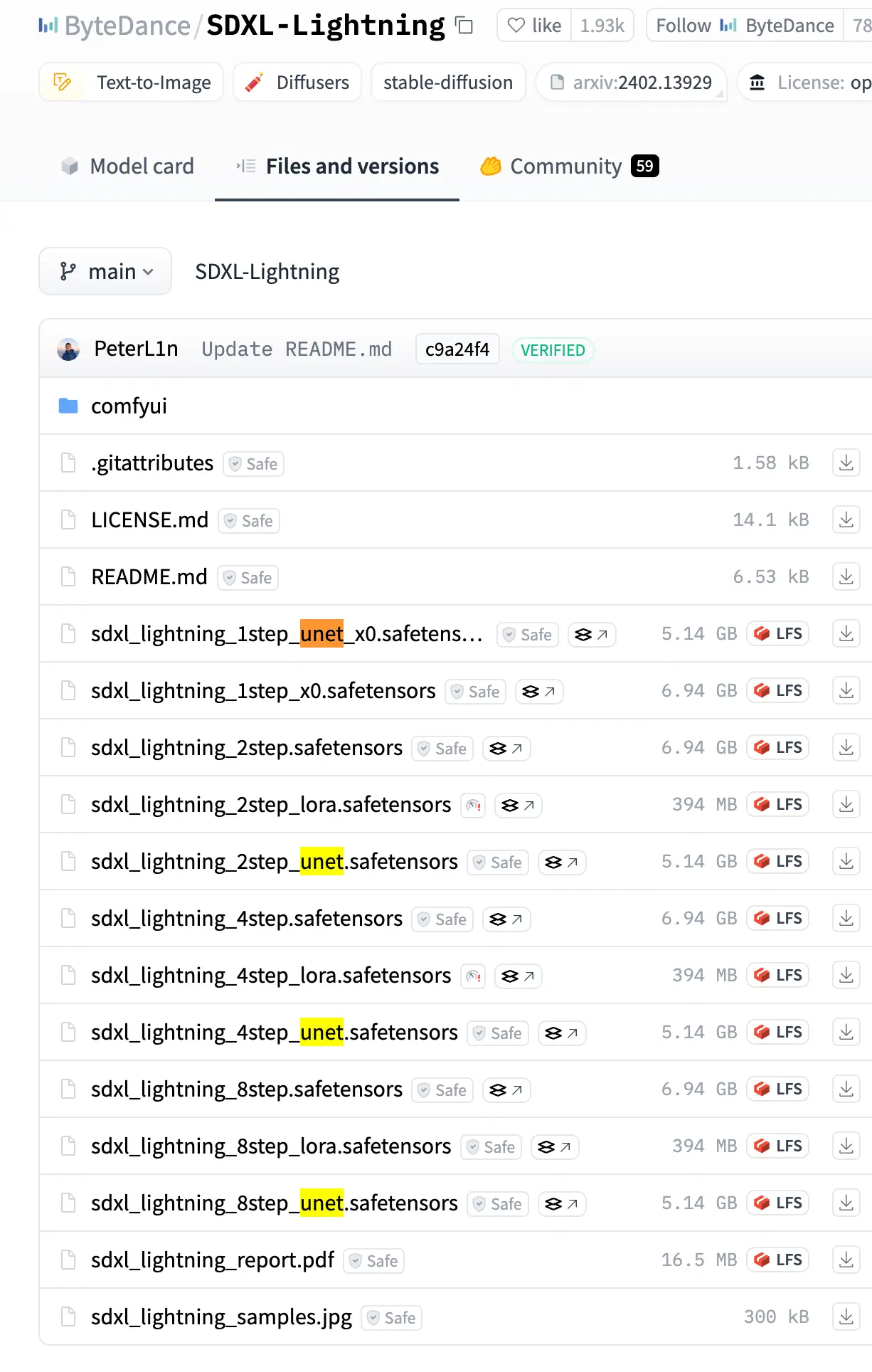
LoRA 则小很多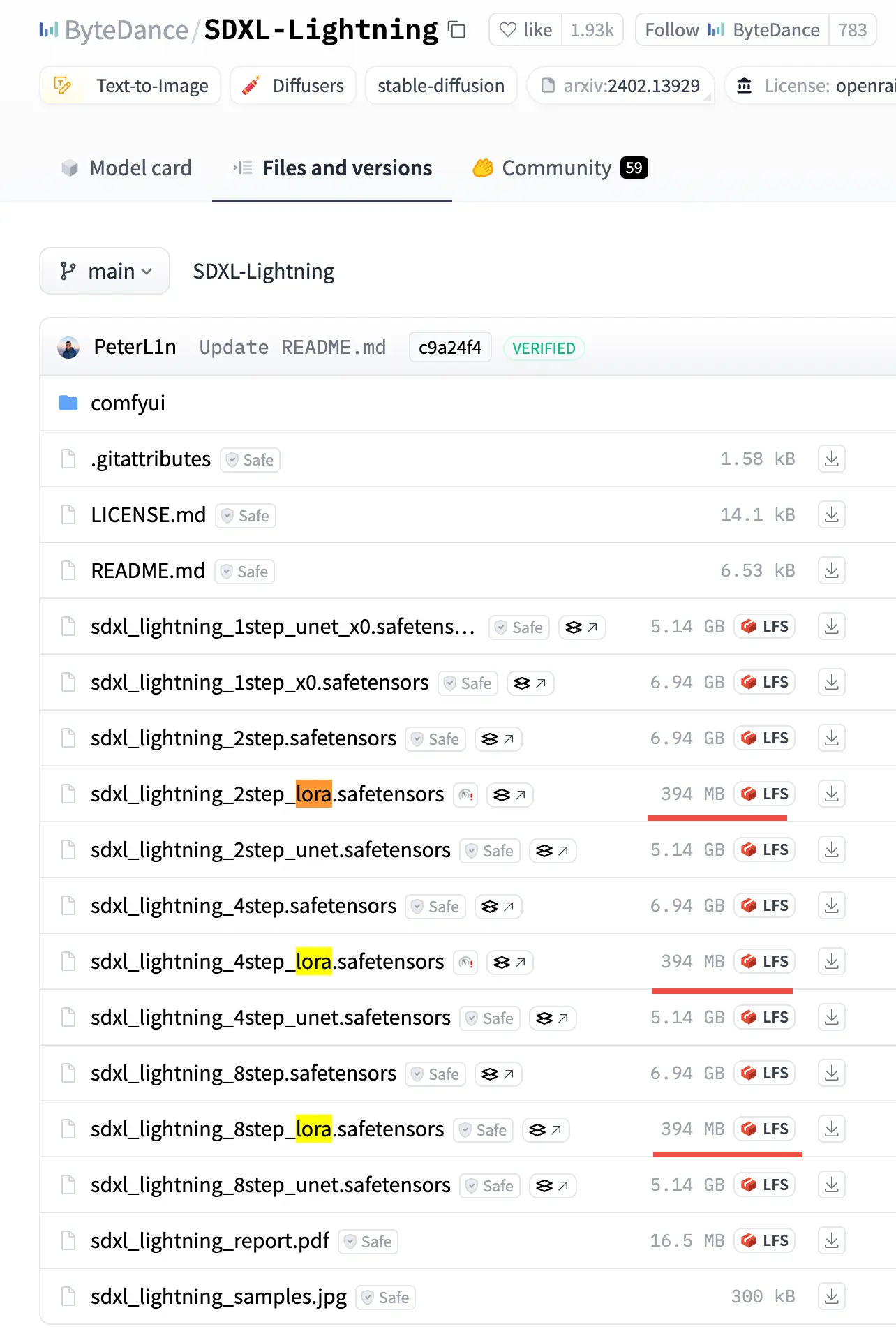
使用
它们都有 2-Step, 4-Step, 8-Step,其中 1-step 只是实验性的、效果不好、质量不稳定,一般建议用折中的 4-step,如果资源充足可以选质量最好的 8-step。
ComfyUI 中的使用非常简单: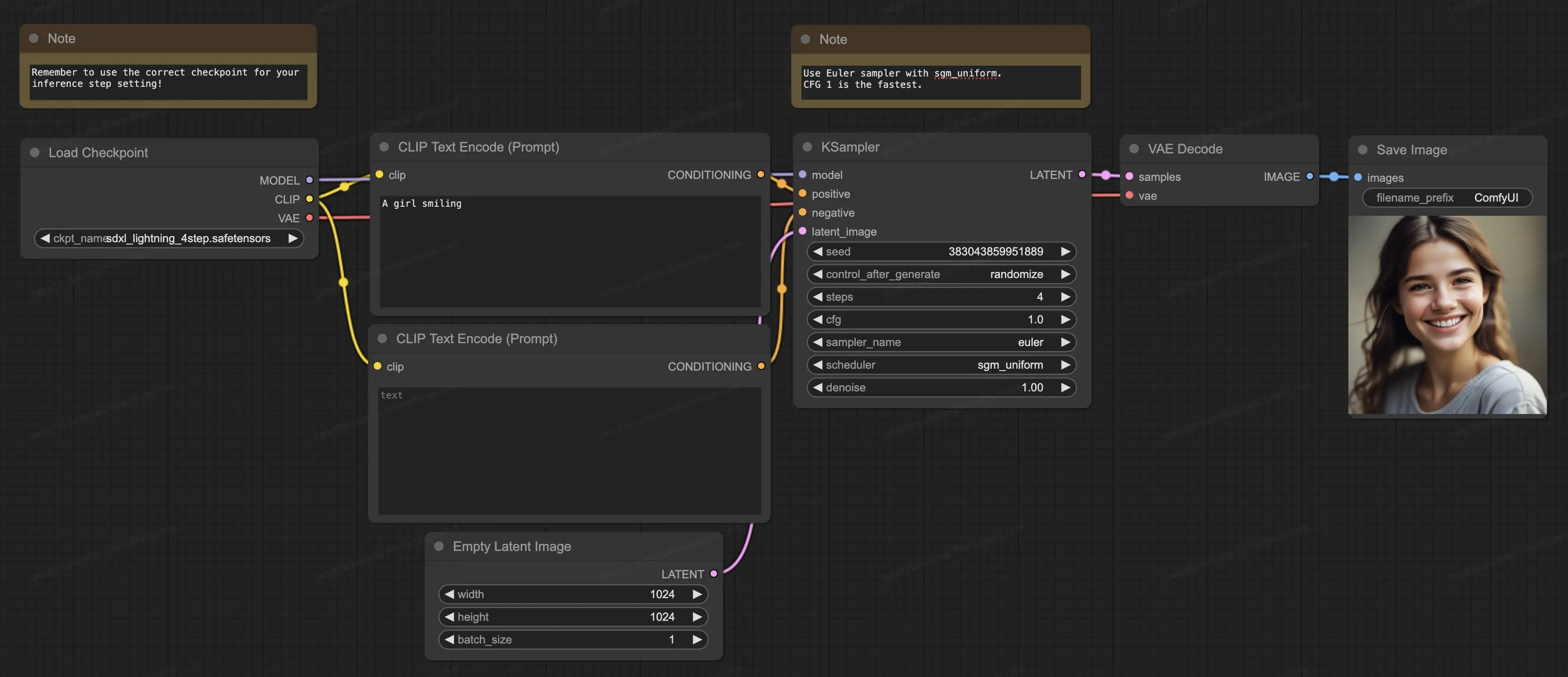
如果只是想玩玩,可以直接在 huggingface 上试试:SDXL-Lightning spaces ,效果还是不错的: